
KL5C8400の"Z80モード"と本家Z80の同一クロック動作でのパフォーマンスを比較してみたいと思います。MSX上で実際に計算をさせてみて時間を測ってみたい!のですが諸事情で環境がないので、ぼちぼちと続けていくつもりです。
この比較の当面の条件は「同一クロック、同一環境での比較」をしようと思っています。つまりMSXのCPUだけを載せ替えての比較を意識しています。メモリアクセスのWAITが変わるとかクロックをできるだけ上げてみるといった内容は別途準備が出来たらやってみようと思います。
最初になんなのですが、大きな期待はできないと思います。メーカーの資料によるとZ80モードの場合約20%、KC80モードで30%くらい速度アップが期待されると記載があったと思います。これは体感にするとおそらく「変わらなくね?」だと思います。
そして自分がZ80にそれほど精通しているわけではありませんので、最適なコード(Z80にとってもKL5C8400にとっても)というものを捻出しきれないと思っています。なので参考までに見ていただけると嬉しいです。それとZ80のセオリー的なものも知識としてないので、例えばとあるサブルーチンについてこういうコードを書くとKL5C8400のほうがこれくらい速い!と言ったところで、そもそもZ80でそのようなコードは書かない。ふつうはこっちの書き方をする。といったようなことは頻出すると思います。残念なことに現時点でこの新さくらのブログにはコメント機能がないためより良い方法のコメントとかをいただけないのが悲しいです。ですが新さくらのブログはまだ新しい機能なようなのでこのあたりは今後に期待しています。
最後に、現時点でKL5C8400を動かせるパソコン環境はYAMAHA CX11(MSX1)のみなのですが、フロッピーディスクなどテストコードを保存しておく環境がないために実機テストがつらい状況です。テストの性格上CPUを取り換えるためにパソコンの電源を落とさなくてはなりませんが、そのたびにコードを書き直すのはしんどいです。こちらについても何とかしていきたいです。
さて前置きが長くなりましたが、今回は机上での比較をしてみようと思います。
ここに「Z80 マシン語秘伝の書」があります。Z80での高速な実装に関する情報満載の秘伝の書であります。ここからいくつかピックアップしてみたいと思います。
まず最初は「問その80 テーブル処理で複雑な計算を」を使って比較してみました。このコードはAレジスタに入力された値(0~255)の2乗を計算してHLレジスタに結果を返すサブルーチンです。実際2乗の計算はせず、あらかじめ計算結果(0*0, 1*1, 2*2, 3*3,...255*255)をメモリ上に置いておき、入力された値をIndexに使い、メモリ上の計算結果を取得して返すという手法です。複雑な計算もこの手法で高速に計算結果を得られます。100*sin(n)を1度刻みとか。
テーブルのデータは2バイトで1つのデータになります。解答はこうでした。
KDATA: DW 0,1,4,9,16,25
DW 36,49,64,81,100
...
DW 63504, 64009, 64516, 65025
; 512Bytes table
XTIMX: LD L,A
LD H,0
ADD HL,HL
LD DE,KDATA
ADD HL,DE
LD E,(HL)
INC HL
LD D,(HL)
EX DE,HL
RETステート数を比較してみます。表の機能がないので画像を貼ります。画像にするとコードのコピペが出来なくなるので上記と二回掲載になりますがご容赦ください。
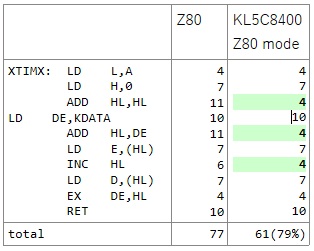
こうしてみると3命令程、Z80に比べ大幅にステート数の少ないものがあります。このためトータルで見て20%ほど速く処理される見込みです。
ADD HL,HLやINC HLといった16bitのレジスタ間計算のステート数がすごく減っています。10ステート以上の命令が2ステートくらい減る(-20%)という命令はほかにも多数あるようです。1命令で20%以上の減となる命令は積極的に使えるといいですね。
既存のプログラムはZ80で最適化されていると思いますので、"積極的に使う"ということは"新しくプログラムを製作する"か"既存コードにKL5C8400用の最適化パッチを製作する"ということになると思います。
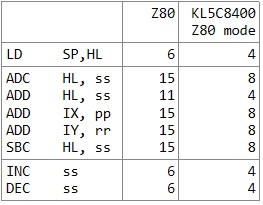
21%以上ステート数の減る命令をリストアップしてみました。
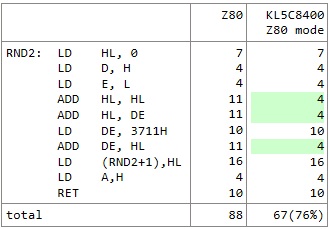
次、秘伝の書をぱらぱらとめくってみると16bit ADD命令が多めのコードが目に留まりました。「問その31 実用的な疑似乱数」です。呼ぶとAレジスタにランダムな値を返します。
RND2: LD HL, 0
LD D, H
LD E, L
ADD HL, HL
ADD HL, DE
LD DE, 3711H
ADD DE, HL
LD (RND2+1),HL
LD A,H
RETこんな短いコードでもすごく速くなる命令が3つもあるので期待しました。ステート数を書き出してみました。24%ほど少なくなっています。思ったほど少なくなりませんでした。2桁サイクル数の命令もあり全体的にサイクル数が多かったので薄まってしまいました。また、ルーチン内でHL, DEを破壊するのでこれを回避する必要がある場合にはPUSH/POPを前後に入れると思います。これによりステート数が増えるので高速化の割合も低くなります。
いいことばかりではない点も机上でですが確認できました。同じく秘伝の書の「問その37 メモリを埋める」です。これは特定のアドレスから120バイトを0で埋めるという課題でした。その解答としてコードは2つ紹介されていました。
1つ目はこちらでAレジスタにある0をHLレジスタの指すメモリに書き出すことをLDIRで繰り返す方法です。
XOR A
LD HL, xxxx
LD DE, xxxx +1
LD BC, 119
LD (HL), A
LDIR
RET繰り返し命令だけ1ステート少なく、ループ回数分だけ処理時間が短くなるようです。ただ、B=0となってループを抜けるときのステート数は変わらないらしく、この時のZ80の16ステートに対して20ステートで少し遅いです。ですので最低5回ループしないと速くはならないということになると思います。

2つ目の解はより速度重視になったコードになっています。LD (HL),Aを繰り返すよりも、2バイトずつかつループ回数を少なめに実行することで速度を稼ぐ方法でした。その際にSPの指すアドレスに書き出すことでアドレスを移動(-2)していく命令を省くことができる書き方がすごいですね。そのかわり割込みが発生すると困るので処理中の割り込みが禁止になっています。
DI
LD (SPPOP +1), SP
LD SP, xxxx + 120
LD HL, 0
LD B, 12
SLOOP:PUSH HL
PUSH HL
PUSH HL
PUSH HL
PUSH HL
DJNZ SLOOP
SPPOP:LD SP,0
EI
RET先ほど書きませんでしたがPUSHに関してはKL5C8400はZ80よりも少し遅い(POPは同じ速度)ようで今回の場合不利になります。さらにはこのコードでは影響は少ないですがDI/EIの命令も遅いです。トータルするとなんと13%遅くなる計算になりました。
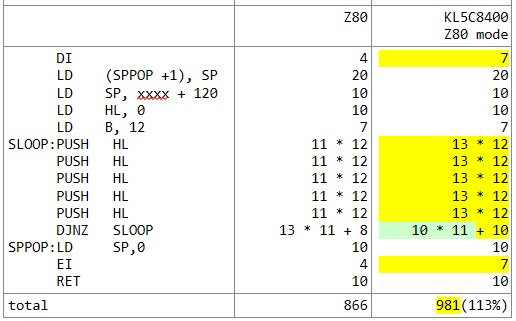
DJNZについてもループを抜けるときのサイクル数は変わらないとのことで、この時Z80よりも遅くなります。
(つづく)